Compared with traditional RGB-only visual tracking, few datasets have been constructed for RGB-D tracking.
In this paper, we propose ARKitTrack, a new RGB-D track-ing dataset for both static and dynamic scenes captured
by consumer-grade LiDAR scanners equipped on Apple’s iPhone and iPad.
ARKitTrack contains 300 RGB-D sequences, 455 targets, and 229.7K video frames in total.
Along with the bounding box annotations and frame-level attributes,
we also annotate this dataset with 123.9K pixel-level target masks. Besides,
the camera intrinsic and camera pose of each frame are provided for future developments.
To demonstrate the potential usefulness of this dataset,
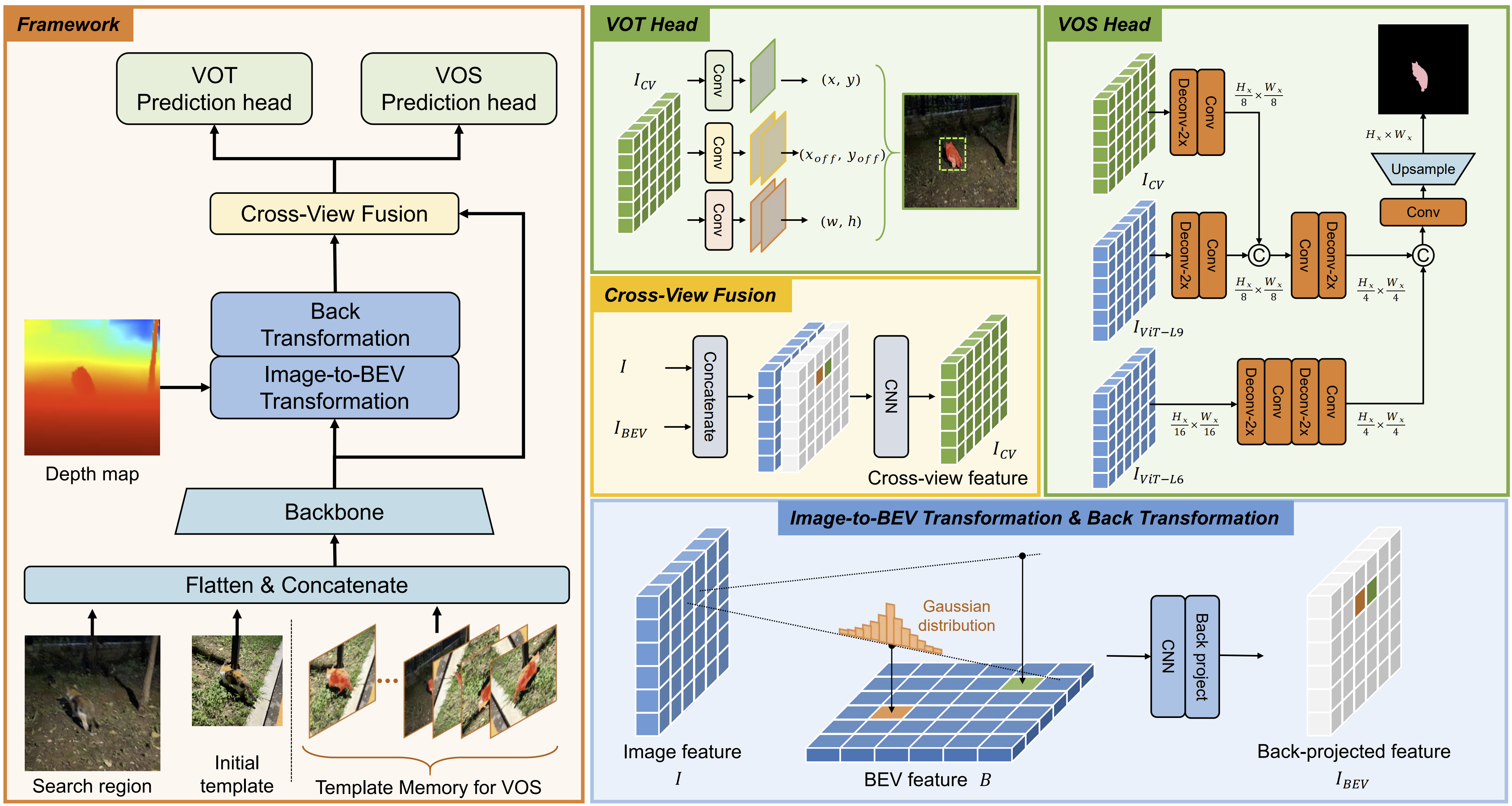
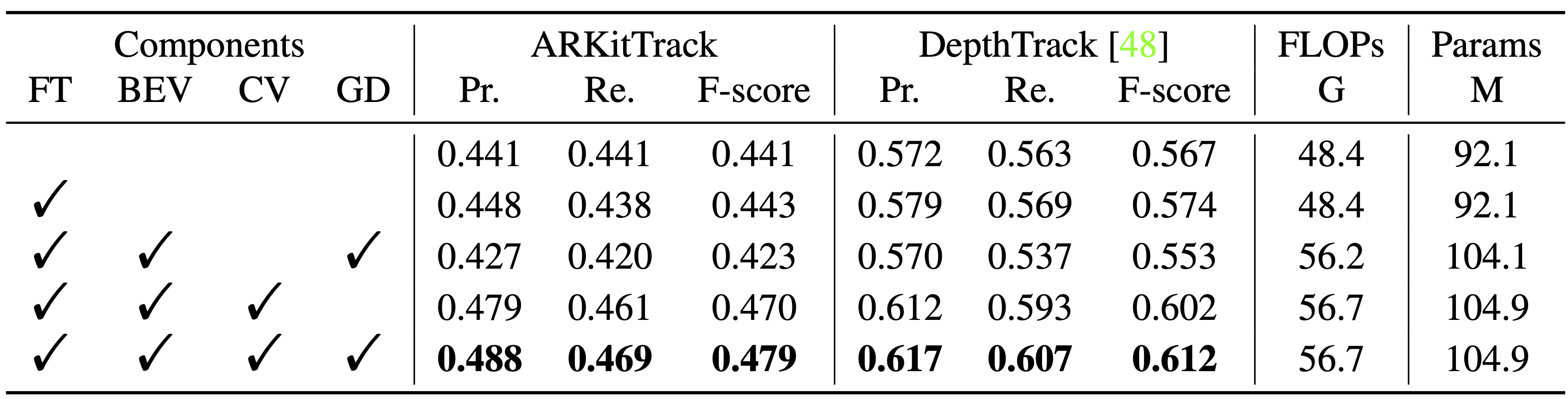
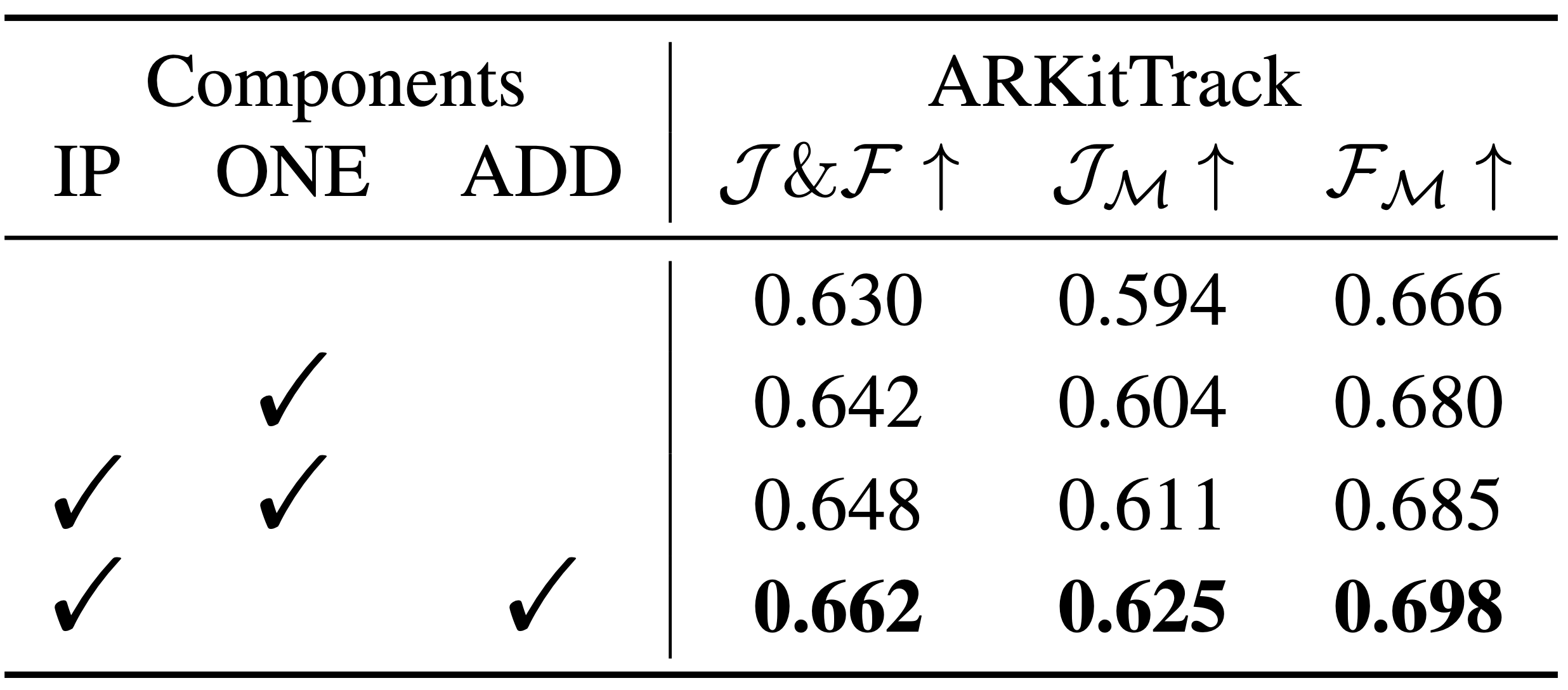
we further present a unified baseline for both box-level and pixel-level tracking,
which integrates RGB features with bird’s-eye-view representations to better explore cross-modality 3D geometry.
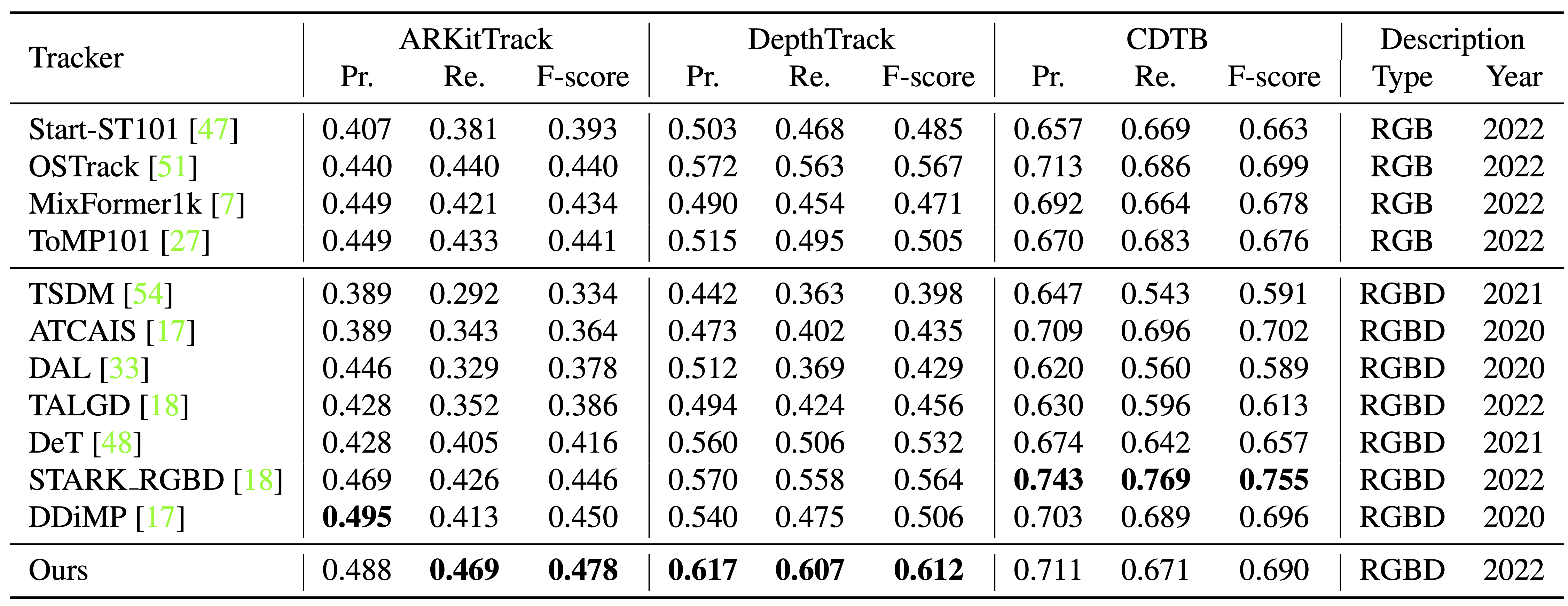
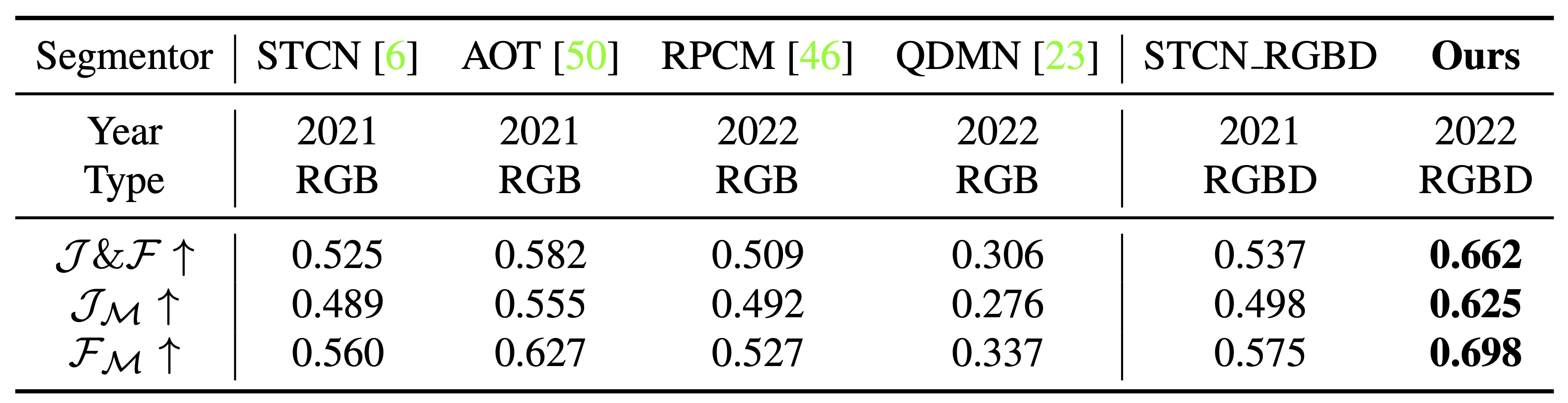
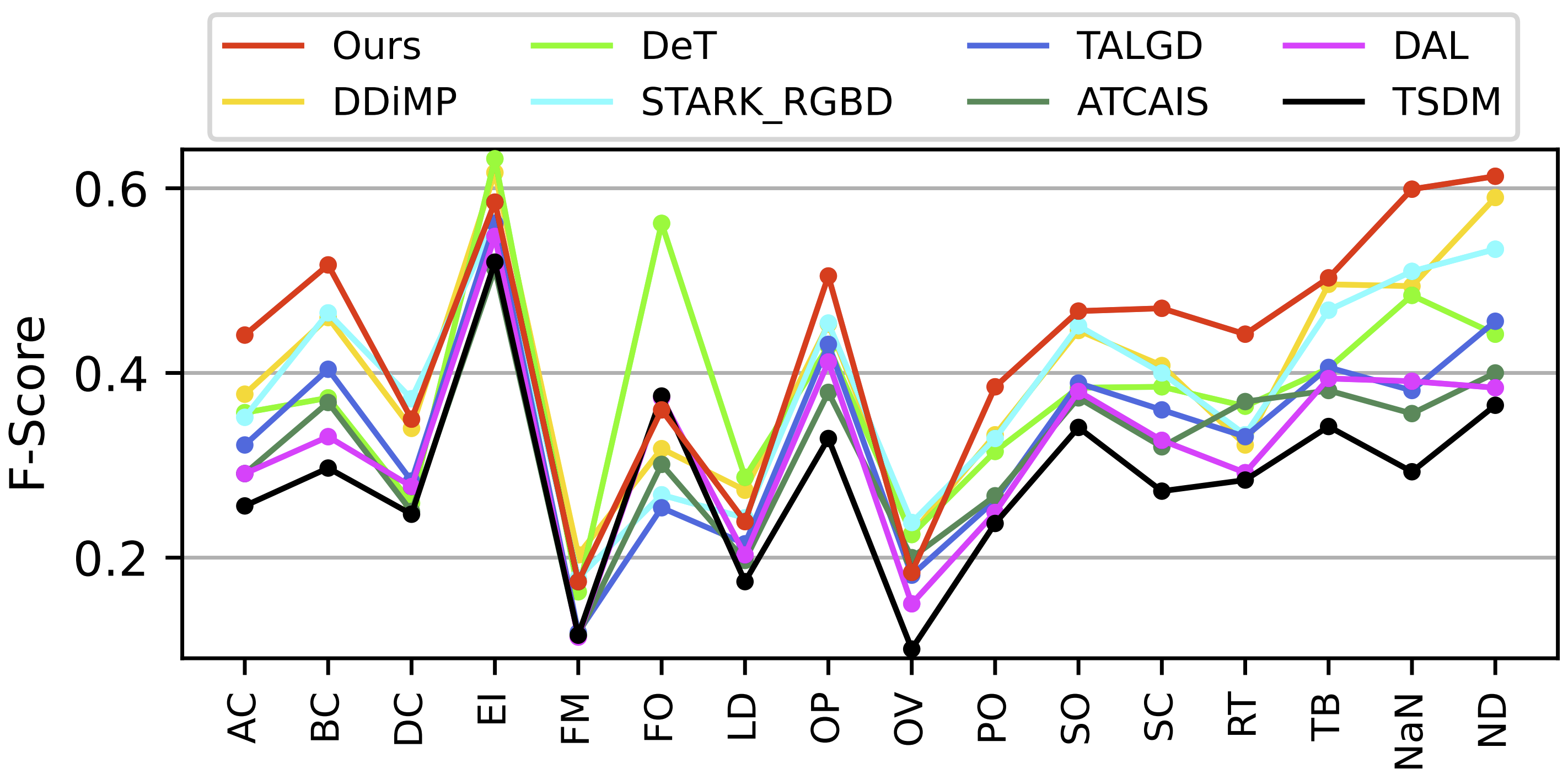
In-depth empirical analysis has verified that the ARKitTrack dataset
can significantly facilitate RGB-D tracking and that
the proposed baseline method compares favorably against the state of the arts.